

Hay una nueva tecnología estelar para entrenar modelos de IA de manera de gran eficiencia. Al menos es lo que Alibaba parece haber mostrado el viernes presentado Su familia de modelos QWEN3-Next y sospechó esto de una eficiencia espectacular que incluso deja a los que manejaron Deepseek R1.
Qué pasó. Alibaba Cloud, el departamento de infraestructura de la nube del Grupo Alibaba, presentó una nueva generación de LLM el viernes descrito como «El futuro de los LLM eficientes». Según los responsables, estos nuevos modelos son 13 veces más pequeños que el modelo más grande que comenzó la compañía, y esto solo se presentó una semana antes. Puedes probar qwen3-next En el sitio web de Alibaba (Recuerde seleccionarlo en el menú de caída en la parte superior izquierda.
Qwen3-next. Esto es lo que se llaman los modelos de esta familia, bajo el cual es particularmente notable. QWEN3-NEXT-80B-A3BLo que es hasta 10 veces más rápido, según los desarrolladores, que el modelo QWEN3-32B comenzó en abril. Lo realmente notable es que es un 90% más rápido con una reducción en los costos de capacitación.
500,000 dólares estadounidenses no son nada. Según el informe del índice de IA GPT-4 OpenAai invirtió $ 78 millones de la Universidad de Stanford en cálculo. Google continuó gastando en Gemini Ultra, y según este estudio, el número fue de $ 191 millones. Se estima que QWEN3-Next solo cuesta $ 500,000 en esta fase de entrenamiento.
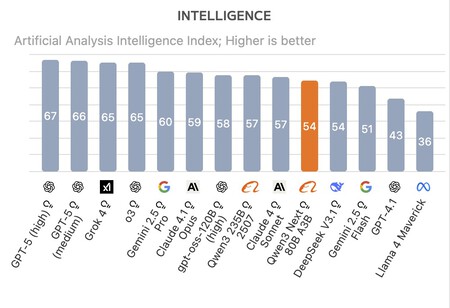
Mejor que sus competidores. Después Puntos de referencia hechos Según el análisis de la compañía artificial, QWEN3-NEXT-80B-A3B logró superar la última versión de Deepseek R1 y Kimi-K2. El nuevo modelo de argumentación de Alibaba no es el mejor término global GPT-5, Grok 4, Gemini 2.5 Pro Claude 4.1 Opus, que lo supera, pero aún logra un rendimiento sobresaliente, teniendo en cuenta los costos de capacitación. ¿Cómo lo hiciste?
Mezcla de expertos. Estos modelos usar La mezcla de arquitectura experta (MOE). Esto significa que el modelo está «dividido» en una especie de subred neural, que se especializa en subgrupos de datos. En este caso, Alibaba aumentó el número de «expertos»: mientras que el Depseek-V3 y Kimi-K2 256 y 384 expertos usan, QWEN3-NEXT-80B-A3B 512 expertos, pero solo activa 10 al mismo tiempo.
Atención híbrida. La clave para esta eficiencia Está en la atención híbrida que se llama SO. Los modelos actuales generalmente ven que su eficiencia se reduce cuando la longitud de entrada es muy larga y «presta más atención», y esto implica más computadoras. En QWEN3-NEXT-80B-A3B se utiliza una tecnología llamada «Deltanet cerrada» Desarrollaron y compartieron Con y nvidia en marzo.
Deltanet cerrado. Esta tecnología mejora la forma en que los modelos son conscientes de cuándo se realizan ciertos ajustes a los datos de entrada. La tecnología determina qué información se puede mantener y cuál puede ser rechazada. Esto permite un mecanismo de costo preciso y súper eficiente. De hecho, QWEN3-NEXT-80B-A3B es comparable al modelo de Alibaba más potente QWERN3-235B-A22B-Female-257.
Modelos eficientes y pequeños. Los crecientes costos para la capacitación de nuevos modelos de IA serán preocupantes, y que han hecho más y más esfuerzos para crear modelos de voz «pequeños» que sean más baratos de entrenar, son más especiales y particularmente eficientes. El mes pasado, Tencent presentó modelos de menos de 7,000 millones de parámetros, y otra startup llamada Z.AI publicó su modelo de aire GLM 4.5 con solo 12,000 millones de parámetros activos. Mientras tanto, los modelos grandes como GPT-5 o Claude usan muchos otros parámetros, lo que hace que el cálculo requerido sea mucho más grande.
En | Si la pregunta es cuál gana la gran tecnología de la carrera de IA, la respuesta es: ninguna










{kind=link}